 01 марта 2012 года в рамках очередной встречи МСР-клуба г. Екатеринбург (http://www.ekbit.pro/), я читал доклад по теме "SQL Server 2012. Columnstore Indexes" - Columnstore-Index.pptx (2,11 mb).
01 марта 2012 года в рамках очередной встречи МСР-клуба г. Екатеринбург (http://www.ekbit.pro/), я читал доклад по теме "SQL Server 2012. Columnstore Indexes" - Columnstore-Index.pptx (2,11 mb).
Прошло совсем немного времени, но я уже получил несколько вопросов по теме моего доклада. Колоночные индексы - одна из ключевых новинок SQL Server 2012, но на данный момент документации в сети не так много, тем более на русском языке, поэтому я решил собрать все ключевые особенности, связанные с использование колоночных индексов (по мотивам http://social.technet.microsoft.com/wiki/contents/articles/3540.sql-server-columnstore-index-faq.aspx).
Кроме того, новая версия SQL Server 2012 уже доступна для скачивания по подпискам MSDN и TechNet. Редакции Microsoft® SQL Server® 2012 Express и Microsoft® SQL Server® 2012 Evaluation доступны всем.
Официальный выход запланированный на 01 апреля 2012.
В какой версии SQL Server впервые появились колоночные индексы (Columnstore Indexes)?
Колоночные индексы впервые появились в SQL Server Denali CTP 3 и являются одной из ключевых фич (feature) новой версии SQL Server 2012. Разработаны в рамках проекта Аполлон (Apollo).
Что такое Apollo?
Apollo (Аполлон) - кодовое название одного из проектов в рамках разработки SQL Server 2012. Основная цель проекта - уменьшить TCO (Total cost of ownership) существенным ускорением запросов к хранилищу данных (data warehouse). В рамках этого проекта в SQL Server появились две новых технологии: колоночные индексы (Columnstore Indexes) и векторная обработка запросов, названная пакетной обработкой (batches).
На какой технологии базируются колоночные индексы?
Отличительная особенность колоночных индексов в том, что они основаны на колоночном хранении данных.
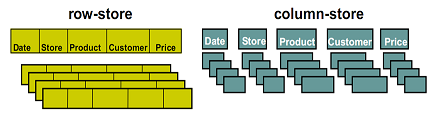
Под построчным хранением данных обычно понимается физическое хранение всей строки таблицы в виде одной записи, в которой поля идут последовательно одно за другим, а за последним полем записи в общем случае идет первое следующей записи. Приблизительно так:
[A1, B1, C1], [A2, B2, C2], [A3, B3, C3]…
где A, B и С — это поля (столбцы), а 1,2 и 3 — номер записи (строки).
Колоночное хранение - с точки зрения SQL-клиента данные представлены как обычно в виде таблиц, но физически эти таблицы являются совокупностью колонок, каждая из которых, по сути, представляет собой таблицу из одного поля. При этом физически на диске значения одного поля хранятся последовательно друг за другом — приблизительно так:
[A1, A2, A3], [B1, B2, B3], [C1, C2, C3] и т.д.
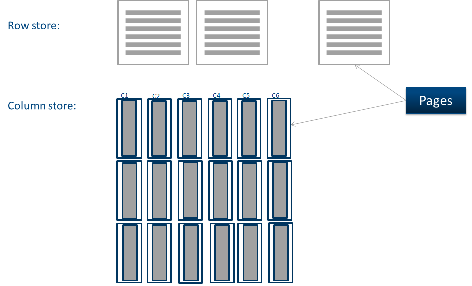
Колоночное хранение - это, что-то новое от Microsoft?
На базе колоночного хранения данных основана работа ряда современных СУБД. Середина 2000-х годов ознаменовалась бурным ростом числа колоночных СУБД. Vertica, ParAccel, Kognito, Infobright, SAND и другие пополнили клуб колоночных СУБД и разбавили гордое одиночество Sybase IQ, основавшей его в 90х годах. При этом колоночное хранение появилось вместе с первыми классическими реляционными СУБД в 70х годах.
Как много колоночных СУБД?
На сегодняшний день это достаточно большой список, как коммерческих так и бесплатных открытых (open source software) продуктов.
Commercial
- Free and open source software
В каких редакциях SQL Server будут доступны колоночные индексы?
Колоночные индексы доступны только в редакциях:
- Enterprise Edition - максимальная редакция
- Evaluation Edition - ознакомительная версия, использование ограничено сроком в 180 дней
- Developer Edition - по функциональным возможностям совпадает с Enterprise Edition, но лицензия накладывает дополнительные эксплуатационные ограничения, предназначена для разработки.
Что необходимо сделать (какие настройки включить), чтобы я мог использовать колоночные индексы?
Для использования колоночных индексов не нужно использовать какие-то особенные параметры установки или запуска SQL Server. Так же не нужно включать дополнительных настроек ни на уровне сервера ни на уровне базы данных. Всё, что необходимо сделать - это построить колоночный индекс на всех или нескольких полях таблицы. Далее оптимизатор сам принимает решение использовать колоночные индексы, если это действительно необходимо. Пакетная обработка так же автоматически используется оптимизатором, когда это возможно.
Как можно создать колоночный индекс?
Синтаксис создания колоночных индексов не сильно-то отличается от синтаксиса создания других типов индексов, главное отличие - это добавление ключевого слова
COLUMNSTORE
create nonclustered COLUMNSTORE index MyColumnStoreIndex on MyTable ( col1, col2, col3 );
Кроме того, создать индекс можно и через графический интерфейс SSMS (SQL Server Management Studio):
- Необходимо выбрать конкретную таблицу и выбрав папку Indexes, щёлкнуть правой кнопкой мыши
- Выбираем в контекстом меню New Index -> Non-Clustered Columnstore Index...
- В открывшемся диалоговом окне нажимаем кнопку Add и выбираем поля, которые нам необходимо включить в колоночный индекс
- Можно выбрать конкретные поля или включить все, щёлкнув по титульной колонке Name. Нажимаем OK
- Включаем, по необходимости, другие настройки (maxdop, filegroup). Нажимаем OK
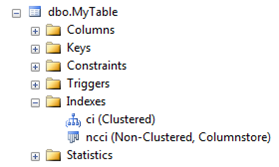
 Отличается ли графически колоночный индекс от других индексов в SSMS?
Отличается ли графически колоночный индекс от других индексов в SSMS?
Да, у колоночных индексов своя, новая иконка:
 Имеет ли значение порядок столбцов, которые я включаю в индекс?
Имеет ли значение порядок столбцов, которые я включаю в индекс?
Нет. После создания колоночного индекса используется собственный алгоритм для организации и сжатия данных.
Должна ли таблица иметь первичный ключ (primary key)?
Нет. Для колоночного индекса нет необходимости в первичном ключе. Кроме того, сам колоночный индекс не может быть использован в качестве первичного (
primary key) или внешнего ключа (
foreign key).
Сколько столбцов может быть включено в колоночный индекс?
В колоночном индексе не существует понятия ключевых столбцов, так что ограничение числа ключевых столбцов в индексе (16) не применяется к колоночным индексам. Ограничение размера записи индекса в 900 байт также не применяется к колоночным индексам.
Максимальное количество столбцов, которые могут быть включены в колоночный индекс - 1024. Если некоторые столбцы таблицы имеют недопустимый тип для колоночного индекса, то их необходимо исключить.
Какие типы данных разрешены для включения в колоночный индекс?
В колоночный индекс могут быть включены столбцы следующих типов:
- int
- bigint
- smallint
- tinyint
- money
- smallmoney
- bit
- float
- real
- char(n)
- varchar(n)
- nchar(n)
- nvarchar(n)
- date
- datetime
- datetime2
- smalldatetime
- time
- datetimeoffset c точностью <=2
- decimal или numeric с точностью <= 18
Какие типы данных не поддерживаются?
Колоночный индекс не поддерживает следующие типы данных:
- decimal или numeric с точностью > 18
- datetimeoffset с точностью > 2
- binary
- varbinary
- image
- text
- ntext
- varchar(max)
- nvarchar(max)
- cursor
- timestamp
- uniqueidentifier
- sqlvariant
- xml
- hierarchyid
- пространственные типы (geography, geometry)
- пользовательские CLR-типы
Может ли колоночный индекс быть кластерным?
Нет. Колоночный индекс может быть только некластерным. Создан он может быть, как на кластеризованой таблице, так и на таблице-куче.
Отличается ли время создания колоночного индекса?
Везде указано, что время создания колоночного индекса в 1,5 раза больше, чем построение Б-дерева, на тех же самых столбцах. Однако в моих экспериментах колоночный индекс создавался быстрее, чем некластерный индекс на тех же самый столбцах.
Поддерживается ли параллелизм при создании колоночного индекса?
Да. При создании колоночного индекса параллелизм может быть задействован. Ограничение накладывается, как числом процессоров, так и явно, настройкой MAXDOP.
Я пытаюсь явно задать распараллеливание при создании колоночного индекса, но индекс создаётся с MAXDOP = 1, почему?
Если размер данных в таблице, для которой вы создаёте колоночный индекс, меньше 1 млн. строк, то распараллеливание не применяется. Кроме того, параллельное создание индекса требует больше памяти, поэтому, если SQL Server не может получить доступ к достаточному объёму памяти, он автоматически уменьшает количество потоков (thread).
Сколько памяти необходимо для создания колоночного индекса?
Объём памяти, необходимый для создания колоночного индекса, зависит от нескольких факторов: числа столбцов, количества строк в таблице, степень параллелизма и характеристики самих данных. Если SQL Server не может получить необходимое количество памяти для создания колоночного индекса, то количество потоков уменьшается автоматически, если памяти не хватает и при MAXDOP = 1, то создание колоночного индекса прерывается ошибкой.
Общая формула для оценки необходимой памяти выглядит следующим образом:
Необходимый объём памяти (MB) = [(4.2 * количество колонок в колоночном индексе) + 68] * Cтепень параллелизма (DOP) + (Количество строковых колонок * 34)
Возможно ли создать колоночный индекс на сжатой таблице?
Да. Базовая таблица может быть создана, как с сжатием PAGE или ROW, так и без использования сжатия. Колоночные индексы при этом использую свой алгоритм сжатия.
Может ли колоночный индекс быть с условием?
Нет. Колоночный индекс должен содержать в себе все строки таблицы.
Можно ли создать колоночный индекс на вычисляемых полях?
Нет. Вычисляемые поля необходимо исключить из колоночного индекса.
Можно ли создать колоночный индекс на разреженных (sparse) столбцах?
Нет. Разреженные столбцы не могут быть часть колоночного индекса.
Можно ли создать колоночный индекс на индексированных представлениях?
Нет. Колоночный индекс не может быть создан на представлении (view).
Может ли колоночный индекс быть уникальным?
Нет. Колоночный индекс не может быть создан с использованием ключевого слова
UNIQUE.
Может ли колоночный индекс быть создан с включенными столбцами?
Нет. Колоночный индекс не может быть создан с использованием ключевого слова
INCLUDE.
Можно ли создать колоночный индекс с параметром SORT_IN_TEMPDB?
Нет. SQL Server вернёт ошибку:
Msg 35317, Level 15, State 1
CREATE INDEX statement failed because specifying SORT_IN_TEMPDB is not allowed when creating a columnstore index. Consider creating a columnstore index without specifying SORT_IN_TEMPDB.
Можно ли создать колоночный индекс в режиме ONLINE?
Нет. SQL Server вернёт ошибку:
Msg 35318, Level 15, State 1
CREATE INDEX statement failed because the ONLINE option is not allowed when creating a columnstore index. Create the columnstore index without specifying the ONLINE option.
Как можно задать сортировку для колоночного индекса?
В колоночном индексе при создании нельзя задавать сортировку для столбцов (
ASC или
DESC). При создании колоночный индекс использует свою сортировку в соответствии с алгоритмом сжатия.
Какое количество колоночных индексов может быть создано на одной таблице?
На одной таблице может быть создан только один колоночный индекс.
Как определить, что колоночный индекс используется в запросе?
Определить, что колоночный индекс используется можно по плану запроса. В графическом плане появились новые иконки.
 В моих запросах всё время происходит сканирование колоночного индекса (Columnstore Index Scan), как мне добиться поиска по индексу (Index Seek)?
В моих запросах всё время происходит сканирование колоночного индекса (Columnstore Index Scan), как мне добиться поиска по индексу (Index Seek)?
Колоночные индексы не поддерживают поиск по индексу, всегда используется сканирование.
Как можно заставить оптимизатор использовать колоночный индекс?
Оптимизатор сам принимает решение, когда использование колоночного индекса более эффективная операция, но вы можете явно указать подсказку (Hint) для оптимизатора, чтобы он задействовал колоночный индекс принудительно.
… from MyTable with ( index ( MyCSIndex ) ) …
Как я могу "отключить" использование колоночного индекса в конкретном запросе?
Для того, чтобы принудительно запретить оптимизатору использовать колоночный индекс, существует два способа: либо указать в подсказках явное использование другого индекса, либо использовать новую подсказку
IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX
select distinct ( SalesTerritoryKey )
from dbo.FactResellerSales
option ( ignore_nonclustered_columnstore_index );
Как колоночные индексы "поднимаются" в память?
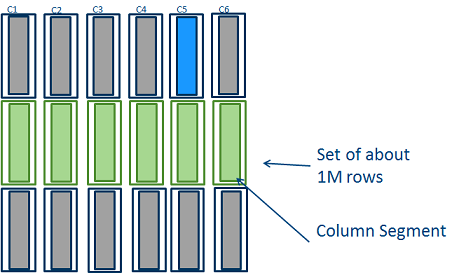
Как и другие индексы, колоночные хранятся на диске. Считывание в память происходит по мере необходимости, как и других индексов. Колоночные индексы разделены на блоки, называемые сегментами (
segments). Сегмент - это единица, которой апеллирует SQL Server. Сегмент хранится в виде LOB и состоит из нескольких страниц. Загрузка в память осуществляется именно сегментами. Наиболее эффективная работа с колоночными индексами может быть достигнута, если весь индекс размещён в памяти. Если индекс находится в памяти, то мы уменьшаем количество операций ввода/вывода (
I/O). Кроме того, в памяти колоночный индекс хранится в формате отличным от того, в котором он хранится на диске. Этот формат оптимизирован под работу современных многопроцессорных серверов .
 Как можно заставить SQL Server загрузить весь колоночный индекс в память?
Как можно заставить SQL Server загрузить весь колоночный индекс в память?
Вы не можете влиять на загрузку или сохранение всего индекса в оперативной памяти, но вы можете выполнить преждевременное чтение всей таблицы, тем самым вы поднимите весь индекс в память.
Когда необходимо использовать колоночные индексы, а когда стоит воздержаться?
Изначально колоночные индексы создавались для оптимизации работы с большими хранилищами данных (
data warehouse queries). Особенно эффективно будут выполняться запросы на схеме типа "звезда" или "снежинка", когда у нас используется большая таблица фактов и относительно небольшие таблицы измерений.
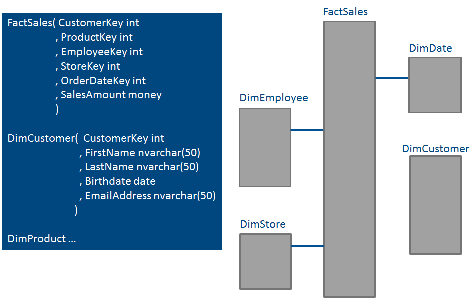
Для небольших таблиц создание колоночного индекса может стать не эффективным. Но в первую очередь вы должны смотреть, насколько эффективна работа с колоночными индексами на ваших конкретных данных, на ваших рабочих нагрузках.

При определённых условиях выигрыш в производительности может увеличится от 10 до 100 раз.
Верное ли утверждение, что создание колоночного индекса делает таблицу неизменяемой (readonly)?
Да. После создания колоночного индекса в таблицу не могут быть внесены изменения. Операторы
INSERT,
UPDATE,
DELETE и
MERGE не поддерживаются.
Если таблица становится readonly, то возможна ли загрузка данных в реальном времени?
Для решения этой проблемы создаётся дополнительная таблица в виде Б-дерева или таблица-куча, которая объединяется с основной таблицей с колоночным индексом. Вторая таблица называется дифференциальной, которая и содержит все вновь загружаемые данные. Периодически, например в ночное время, осуществляется переключение (перенос) диф-данных в основную таблицу. Способы переноса будут рассмотрены ниже.
Поддерживают ли колоночные индексы прозрачное шифрование данных?
Да.
Могу ли я сжать колоночный индекс?
Нет. Колоночный индекс автоматически сжимается при создании, при этом используется Патентованная технология Microsoft
VertiPaq. Это сжатие является более эффективное, чем сжатие типа PAGE и ROW. Пользователи не могут влиять или контролировать сжатие колоночного индекса.
Какой размер на диске занимает колоночный индекс?
Эксперименты показывают, что в зависимости от данных, колоночный индекс в 4 - 15 раз меньше чем базовая таблица.
Колоночные индексы работают с секционированными таблицами?
Да. Колоночный индекс может быть создан на секционированной таблице. Никаких изменений в синтаксис добавлять не нужно. При этом он должен быть выровнен по секциям с базовой таблицей. Таким образом, колоночный индекс может быть создан на секционированной таблице, если столбец секционирования является одним из столбцов в индексе. Если вы попытаетесь создать колоночный индекс в другой файловой группе, то получите ошибку.
Так как же всё-таки вносить изменения в таблицу, на которой построен колоночный индекс?
Для обновления данных существует два основных сценария.
1) Перед загрузкой необходимо удалить или отключить колоночный индекс.

alter index MyColumnStoreIndex on MyTable disable;
-- Изменяем данные --
alter index MyColumnStoreIndex on MyTable rebuild;
2) Использование секционирования.
 Что произойдёт, если я попытаюсь обновить таблицу с колоночным индексом привычными операторами?
Что произойдёт, если я попытаюсь обновить таблицу с колоночным индексом привычными операторами?
Обновление завершится ошибкой.
Если таблица секционирована, то могу ли я перестраивать индекс только на одной секции?
Нет. Отключение или перестроение колоночного индекса возможно только на всей таблице целиком. Но вы можете переключить одну из секций в пустую таблицу и уже на ней произвести манипуляции с колоночным индексом, а значит и над самими данными.
Как узнать, что на таблице создан колоночный индекс?
Один из способов - это посмотреть в Object Explorer клиентского приложения Management Studio. Как уже было показано выше, у колоночного индекса своя новая иконка. Другой способ - это DMV
sys.indexes, где у колоночного индекса поле type = 6, а поле type_desc = 'NONCLUSTERED COLUMNSTORE'.
Какие системные представления могут мне показать более детальную информацию о колоночных индексах?
В SQL Server 2012 появились два новых системных представления для работы с колоночными индексами
- sys.column_store_segments
- sys.column_store_dictionaries
У колоночного индекса каждая секция сжимается отдельно?
Да. Каждая секция сжимается отдельно. Каждая секция имеет свой собственный независимый словарь, это позволяет переключать секции на уровне метаданных.
Как определить какой объём занимает колоночный индекс?
Для ответа на этот вопрос мы можем воспользоваться новыми системными представлениями:
-- total size
with total_segment_size as (
SELECT
SUM (css.on_disk_size)/1024/1024 AS segment_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_segments AS css
ON p.hobt_id = css.hobt_id
)
,
total_dictionary_size as (
SELECT SUM (csd.on_disk_size)/1024/1024 AS dictionary_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_dictionaries AS csd
ON p.hobt_id = csd.hobt_id
)
select
segment_size_mb,
dictionary_size_mb,
segment_size_mb + isnull(dictionary_size_mb, 0) as total_size_mb
from total_segment_size
left outer join total_dictionary_size
on 1 = 1
go
-- size per index
with segment_size_by_index AS (
SELECT
p.object_id as table_id,
p.index_id as index_id,
SUM (css.on_disk_size)/1024/1024 AS segment_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_segments AS css
ON p.hobt_id = css.hobt_id
group by p.object_id, p.index_id
) ,
dictionary_size_by_index AS (
SELECT
p.object_id as table_id,
p.index_id as index_id,
SUM (csd.on_disk_size)/1024/1024 AS dictionary_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_dictionaries AS csd
ON p.hobt_id = csd.hobt_id
group by p.object_id, p.index_id
)
select
object_name(s.table_id) table_name,
i.name as index_name,
s.segment_size_mb,
d.dictionary_size_mb,
s.segment_size_mb + isnull(d.dictionary_size_mb, 0) as total_size_mb
from segment_size_by_index s
JOIN sys.indexes AS i
ON i.object_id = s.table_id
and i.index_id = s.index_id
left outer join dictionary_size_by_index d
on s.table_id = s.table_id
and s.index_id = d.index_id
order by total_size_mb desc
go
-- size per table
with segment_size_by_table AS (
SELECT
p.object_id as table_id,
SUM (css.on_disk_size)/1024/1024 AS segment_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_segments AS css
ON p.hobt_id = css.hobt_id
group by p.object_id
) ,
dictionary_size_by_table AS (
SELECT
p.object_id AS table_id,
SUM (csd.on_disk_size)/1024/1024 AS dictionary_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_dictionaries AS csd
ON p.hobt_id = csd.hobt_id
group by p.object_id
)
select
t.name AS table_name,
s.segment_size_mb,
d.dictionary_size_mb,
s.segment_size_mb + isnull(d.dictionary_size_mb, 0) as total_size_mb
from dictionary_size_by_table d
JOIN sys.tables AS t
ON t.object_id = d.table_id
left outer join segment_size_by_table s
on d.table_id = s.table_id
order by total_size_mb desc
go
-- size per column
with segment_size_by_column as (
SELECT
p.object_id as table_id,
css.column_id,
SUM (css.on_disk_size)/1024/1024.0 AS segment_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_segments AS css
ON p.hobt_id = css.hobt_id
GROUP BY p.object_id, css.column_id
),
dictionary_size_by_column as (
SELECT
p.object_id as table_id,
csd.column_id,
SUM (csd.on_disk_size)/1024/1024.0 AS dictionary_size_mb
FROM sys.partitions AS p
JOIN sys.column_store_dictionaries AS csd
ON p.hobt_id = csd.hobt_id
GROUP BY p.object_id, csd.column_id
)
select
t.name as table_name,
c.name as column_name,
s.segment_size_mb,
d.dictionary_size_mb,
s.segment_size_mb + isnull(d.dictionary_size_mb, 0) total_size_mb
from segment_size_by_column s
join sys.tables AS t
ON t.object_id = s.table_id
join sys.columns AS c
ON c.object_id = s.table_id
and c.column_id = s.column_id
left outer join dictionary_size_by_column d
on s.table_id = d.table_id
and s.column_id = d.column_id
order by total_size_mb desc
go
Используют ли колоночные индексы статистику?
Колоночный индекс в отличие от классических индексов не создаёт автоматически статистику при своём создании. Оптимизатор будет использовать статистические данные, которые существуют у таблицы. Но сам колоночный индекс не использует и не хранит статистические данные в форме традиционного индекса. Более подробно можно ознакомиться по ссылке -
Using Statistics with Columnstore Indexes.
Существуют ли, какие-нибудь особенные рекомендации для управления файловыми группами для колоночных индексов?
Нет. В данном случае используются те же рекомендации, что и для кластерных индексов больших таблиц -
Fast Track Data Warehouse 3.0 Reference Guide.
Может ли колоночный индекс использоваться в технологии FILESTREAM?
Да. Хотя FILESTREAM столбец не может быть включен в колоночный индекс, другие столбцы таблицы могут.
Есть ли понятие колоночный индекс в SQL Azure?
Нет, ещё нет.
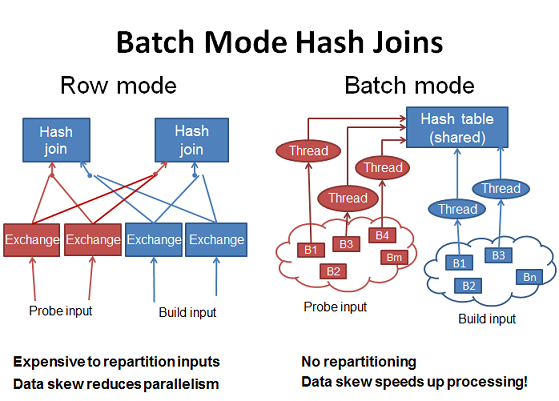
Что такое пакетная обработка (batch)?
Пакетная обработка - это ещё одно новшество SQL Server 2012, разработанное в рамках проекта Аполлон. Это новый режим работы с данными основное отличие которого в том, что обработка идёт не построчно, а пакетами по 1000 записей. Каждый столбец в пакете хранится в виде вектора в отдельной области памяти, поэтому пакетная обработка происходит в векторном режиме. Кроме того, пакетная обработка оптимизирована под современные многоядерные процессоры. Алгоритм работы строится на том, что доступ к метаданным и все накладные расходы связаны с пакетом, а не с каждой строкой, что позволяет уменьшить общую стоимость. Пакетная обработка происходит на сжатых данных, когда это возможно и позволяет уменьшить количество операторов, которые используются при строчной работе. Результатом всех этих плюсов является более производительная работа с улучшенным параллелизмом.
Как я могу определить, что обработка происходит в пакетном режиме?
Пакетная обработка доступна не для всех операторов. Большинство запросов, в которых используется пакетная обработка, включают в себя в том числе и строчную обработку. Узнать используется ли пакетный режим можно в первую очередь с помощью графического плана выполнения запроса. Если вы посмотрите на свойства какого-нибудь оператора на графическом плане, то увидите два новых свойства:
EstimatedExecutionMode и
ActualExecutionMode. Значением этих свойств может быть, как строка, так и пакет.
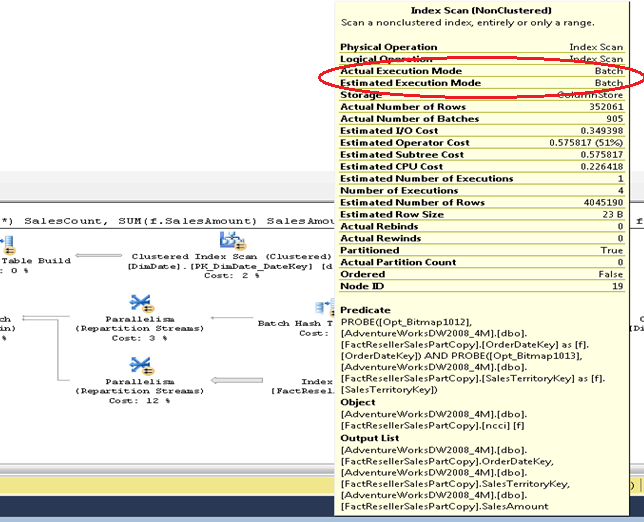
Так же появился новый оператор для хэш-соединений, когда они выполняются в пакетном режиме. Название нового оператора -
BatchHashTableBuild.

 Могут ли отличаться значения EstimatedExecutionMode и ActualExecutionMode? Когда и почему?
Могут ли отличаться значения EstimatedExecutionMode и ActualExecutionMode? Когда и почему?
Оптимизатор запросов выбирает, использовать ли режим пакетной обработки, когда он формулирует план запроса. В большинстве случаева EstimatedExecutionMode и ActualExecutionMode будут иметь одинаковые значения. Две основные причины, когда план может быть выбран в режиме строк, а не пакета - это недостаток памяти или потоков (threads). Наиболее распространенной причиной, когда ActualExecutionMode является "строка", а EstimatedExecutionMode имеет значение "пакет" - это наличие большого хэш-соединения при котором хэш-таблицы не могут поместиться в память. Пакетная обработка использует специальные хэш-таблицы, которые должны располагаться в памяти. Если памяти не достаточно, то оптимизатор выполняет обработку в режиме строк с классическими хэш-таблицами, которые можно сбрасывать на диск. Другая причина - это недостаточное количество потоков для параллельной обработки. Последовательная обработка всегда идёт в построчном режиме.
Если ваш запрос выполнялся в пакетном режиме, но со временем вы заметили, что выполнение стало происходить в режиме строк, то можно сделать вывод, что у вас проблемы с памятью. Для мониторинга нехватки памяти для хэш-соединений появилось новое расширенное событие (XEvent) -
batch_hash_table_build_bailout.
Можно ли использовать пакетный режим обработки, если у меня нет колоночных индексов?
Нет. Пакетная обработка возможна только при наличии колоночного индекса.
Какие ещё операторы могут работать в пакетном режиме?
Общий список операторов, которые поддерживают пакетный режим:
- Filter
- Project
- Scan
- Local hash (partial) aggregation
- Hash inner join
- (Batch) hash table build
Это ответы не на все вопросы, связанные с особенностями использования колоночных индексов, но я постараюсь со временем его дополнить!
Ссылки по теме
- Columnstore Indexes (Product documentation)
- SQL Server Columnstore Index FAQ
- White paper (Columnstore Indexes for Fast DW QP)
- SQL Server Columnstore Performance Tuning Guide
- Using Statistics with Columnstore Indexes
- Fast Track Data Warehouse 3.0 Reference Guide
- Column-oriented DBMS
- Колоночные СУБД — принцип действия, преимущества и область применения
 Подписаться
Подписаться